Bu yazı, conformal prediction'a sezgisel ve teorik bir giriş sunmayı amaçlamaktadır. Amaç, derin matematiksel detaylara girmeden bu yaklaşımın neden önemli olduğunu, hangi probleme cevap verdiğini ve nasıl düşünülmesi gerektiğini netleştirmektir. Devam eden yazılarda ise konunun matematiksel altyapısı, teorik sonuçları, ispatları ve uygulama boyutu daha ayrıntılı şekilde ele alınacaktır.
Bir makine öğrenmesi modeli düşünelim.
Bir hastaya tanı koyuyor. Bir kredi başvurusunu değerlendiriyor. Bir işlemin dolandırıcılık şüphesi taşıyıp taşımadığını söylüyor. Model çıktısını veriyor: "pozitif", "negatif", "riskli", "güvenli".
İlk bakışta her şey yolunda gibi görünüyor. Sonuçta model bir tahmin yaptı.
Ama gerçek hayatta asıl soru çoğu zaman burada başlamıyor. Asıl soru şurada başlıyor:
Bu tahmine ne kadar güvenebiliriz?
Çünkü çoğu uygulamada mesele yalnızca doğru cevabı bulmak değildir. Mesele, modelin hangi durumlarda gerçekten güçlü bir sinyal verdiğini, hangi durumlarda ise kararsız kaldığını anlayabilmektir. Bazen iki model aynı kararı verir, ama bu kararların güven düzeyi aynı değildir. Biri zor örneklerde bile aşırı özgüvenli davranabilir. Diğeri ise belirsizliği daha dürüst bir şekilde yansıtabilir.
İşte makine öğrenmesinde belirsizlik nicelendirmesi bu yüzden önemlidir. Bir modelin yalnızca ne söylediğini değil, bunu ne kadar sağlam bir zeminde söylediğini de bilmek isteriz. Çünkü üretim ortamında, özellikle yüksek riskli alanlarda, tahminin kendisi kadar tahminin güvenilirliği de karar sürecinin bir parçasıdır.
Conformal prediction tam bu noktada devreye girer. Bu yaklaşım, bir modelin verdiği tahminin etrafına istatistiksel bir güven çerçevesi eklemeyi amaçlar. Başka bir deyişle, yalnızca "cevap" üretmekle yetinmez; o cevabın ne kadar güvenle sunulabileceğini de daha sistematik biçimde ifade etmeye çalışır.
Bu yazıda conformal prediction'ı koddan bağımsız, daha çok theory behind tarafına odaklanarak ele alacağım. Amacım formüllere boğmak değil; önce neden böyle bir yaklaşıma ihtiyaç duyduğumuzu, sonra da bu yöntemin temel sezgisini netleştirmek.
Neden belirsizlik ölçümü bu kadar önemli?
Makine öğrenmesi üzerine konuşurken çoğu zaman accuracy, F1-score, ROC-AUC gibi metriklerle başlıyoruz. Bunlar elbette önemli. Ama hepsi temelde modelin geçmiş veride ortalama olarak ne kadar iyi performans gösterdiğini anlatıyor. Oysa gerçek dünyada kararlar tek tek örnekler üzerinden veriliyor.
Bir doktorun önüne gelen tek bir hasta için mesele, modelin genel doğruluğunun yüzde kaç olduğu değildir. O hasta için verilen tahminin ne kadar güvenilir olduğudur.
Bir bankanın kredi başvurusunu değerlendirirken sorduğu soru da yalnızca "model ne dedi?" değildir. "Model bu kararı ne kadar emin olarak verdi?" sorusu da en az onun kadar kritiktir.
Bir dolandırıcılık tespit sisteminde ise bu daha da nettir. Bazı işlemler bariz biçimde şüphelidir. Bazıları ise sınırdadır. Eğer model tüm örneklere aynı özgüven tonuyla yaklaşırsa, sistem dışarıdan güçlü görünse de içeride ciddi bir sorun taşıyor olabilir. Çünkü belirsizliğini saklayan bir model, çoğu zaman olduğundan daha güvenilir görünür.
Makine öğrenmesindeki en büyük pratik problemlerden biri de tam budur: Modeller çoğu zaman bir çıktı vermek zorunda hisseder, ama bu çıktının arkasındaki tereddüdü açıkça göstermez.
Oysa insan uzmanlar böyle davranmaz. Deneyimli bir doktor bazen "Bu bulgu güçlü görünüyor" der, bazen de "Burada emin değilim, ek test isteyelim" der. İyi karar verme, yalnızca cevap üretmek değil; cevabın sınırlarını da bilmektir.
Bu yüzden belirsizlik nicelendirmesi yalnızca teknik bir lüks değildir. Operasyonel olarak da gereklidir. Çünkü belirsizlik görünür hale geldiğinde şunlar mümkün olur:
- Zor örnekleri insan incelemesine yönlendirmek
- Yüksek riskli kararları daha dikkatli ele almak
- Modelin aşırı özgüvenli hatalarını daha erken fark etmek
- Karar sistemlerini daha şeffaf ve daha güvenilir hale getirmek
Kısacası, doğru tahmin yapmak başka şeydir; hangi tahminlere güvenebileceğimizi bilmek bambaşka bir şeydir.
Point prediction neden yetmez?
Klasik makine öğrenmesi modelleri çoğu zaman bize tek bir çıktı verir.
Bir sınıflandırma modeliyse tek bir etiket döndürür: "kedi", "köpek", "spam", "spam değil".
Bir regresyon modeliyse tek bir sayı verir: "yarın sıcaklık 15 derece", "evin fiyatı 8 milyon", "müşteri yaşam boyu değeri 12.400 TL".
Bu tür çıktılar kullanışlıdır, çünkü nettir. Ama tam da bu netlik yüzünden bazen yanıltıcı olabilirler.
Bir sınıflandırma örneği düşünelim. Model iki farklı müşteri için de "ayrılmayacak" tahmini versin. Yüzeyde aynı cevap var. Ama ilk müşteri için model karardan çok emin olabilir; ikinci müşteri içinse karar aslında oldukça sınırda olabilir. Tek etiketli çıktı bu farkı gizler.
Benzer durum regresyonda da geçerlidir. Bir model iki farklı gün için de "yarın sıcaklık 15 derece" diyebilir. Ama ilk durumda gerçek belirsizlik çok düşük olabilir, ikinci durumda ise tahminin etrafında geniş bir belirsizlik bandı olabilir. Yani aynı nokta tahmini, tamamen farklı güven yapıları taşıyabilir.
Buradaki temel problem şu:
Point prediction bize merkez tahmini verir, ama riskin boyutunu söylemez.
Gerçek dünyada ise çoğu karar yalnızca merkeze bakarak verilmez. Karar verici, tahminin ne kadar oynak olduğunu, ne kadar güvenilir olduğunu, ne kadar temkinli yorumlanması gerektiğini de bilmek ister.
İşte tam bu nedenle birçok alanda yalnızca tek bir etiket ya da tek bir sayı yeterli değildir. Daha zengin bir çıktı biçimine ihtiyaç duyarız. Bazen tek bir label yerine bir olası etiketler kümesi, bazen tek bir sayı yerine bir tahmin aralığı görmek isteriz.
Conformal prediction'ın en güçlü yanlarından biri de budur: modelin ürettiği cevabı doğrudan değiştirmek zorunda kalmadan, o cevabın etrafına daha anlamlı bir güven yapısı inşa eder.
Conformal prediction'ın temel sezgisi
Conformal prediction ilk bakışta teknik bir yöntem gibi görünebilir. Ama arkasındaki temel fikir aslında oldukça sezgiseldir:
Yeni gelen bir örnek, daha önce gördüğümüz örneklere ne kadar uyuyor?
Bu sorunun cevabı, tahminin güvenilirliği hakkında bize önemli bir sinyal verir.
Eğer yeni örnek, eğitim ve kalibrasyon sürecinde gördüğümüz örneklere benzer davranıyorsa, modelin bu örnek üzerindeki tahmini daha güvenilir olabilir. Ama yeni örnek alışılmadık, sınırda ya da "uyumsuz" görünüyorsa, o zaman modelin verdiği tek cevaba körü körüne güvenmek yerine daha dikkatli olmak gerekir.
Conformal prediction bu sezgiyi sistematik hale getirir. Bunu yaparken genellikle şu mantıkla ilerler:
Önce elimizde, modelin davranışını gözlemleyebileceğimiz bir kalibrasyon kümesi bulunur. Bu kümedeki örnekler üzerinde modelin tahminleriyle gerçek sonuçlar arasındaki "uyumsuzluk" ölçülür. Ardından yeni bir örnek geldiğinde, bu örneğin olası çıktıları için benzer bir uyumsuzluk değerlendirmesi yapılır.
Sonra kritik soru gelir: Bu yeni örnek, geçmişte gördüğümüz uyumsuzluk seviyelerine göre ne kadar sıradışı?
Eğer çok sıradışı değilse, o çıktı makul kabul edilir. Eğer fazla uyumsuzsa, o çıktı tahmin kümesinin dışında bırakılır.
Bu yüzden conformal prediction'ı yalnızca "bir tahmin tekniği" olarak görmek eksik olur. Aslında o, bir tahminin etrafına istatistiksel bir kabul-red çerçevesi koyar.
Yani model artık sadece "cevap" vermez. Aynı zamanda hangi cevapların makul, hangilerinin fazla riskli olduğunu da daha görünür hale getirir.
Classification tarafında ne değişir?
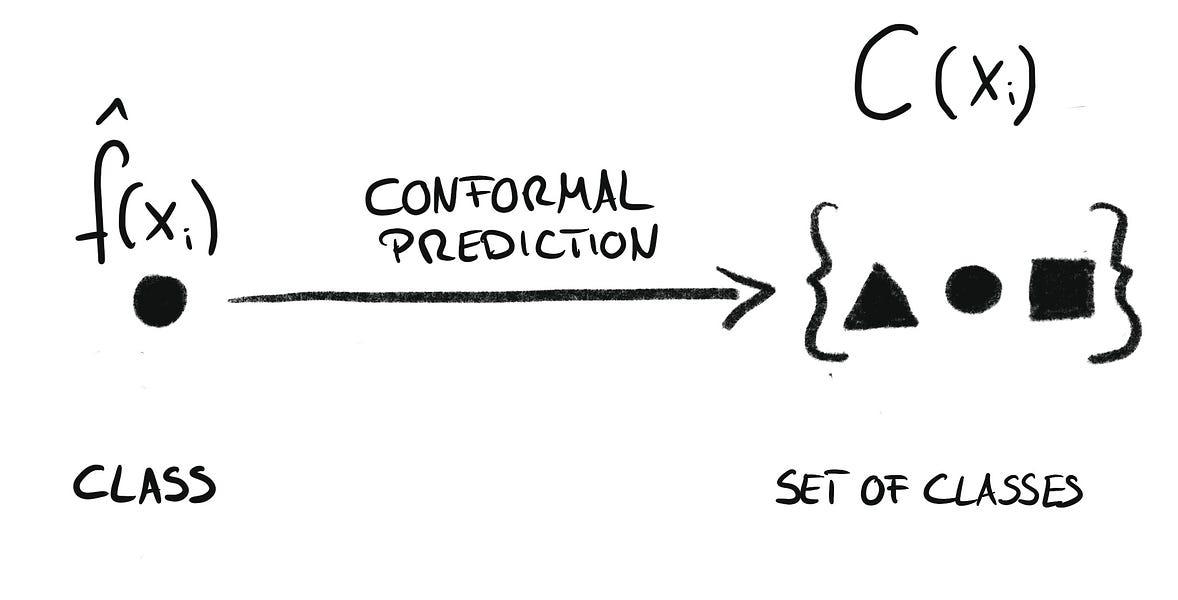
Sınıflandırma problemlerinde klasik model genellikle tek bir etiket verir. Conformal prediction ise bunun yerine çoğu zaman bir prediction set üretir.
Yani çıktı her zaman tek bir sınıf olmak zorunda değildir. Bazen yalnızca {A} döner. Bu, modelin görece net olduğunu gösterir. Bazen {A, B} döner. Bu durumda model, A'nın daha güçlü aday olabileceğini düşündüğü halde B'yi de tamamen dışlayamıyordur. Bazı zor örneklerde küme daha geniş olabilir.
İşte bu davranış çok değerlidir. Çünkü modelin kararsızlığını gizlemek yerine görünür hale getirir.
Geleneksel sınıflandırıcı çoğu zaman zor bir örnekte bile tek bir cevap vermek zorundadır. Conformal prediction ise "Bu örnek için tek bir sınıf söylemek fazla iddialı olur" deme imkânı sunar.
Bu bakış açısı özellikle yüksek riskli uygulamalarda çok önemlidir. Çünkü bazı örneklerde amaç her ne pahasına olursa olsun kesin konuşmak değil, gerektiğinde daha temkinli olmaktır.
Burada güzel bir zihinsel çerçeve şudur:
- Küçük tahmin kümesi, daha yüksek kesinlik anlamına gelir.
- Daha geniş tahmin kümesi, daha fazla belirsizlik taşıdığını gösterir.
- Belirsizlik görünür hale geldiğinde, sistem daha dürüst ve daha yönetilebilir olur.
Kısacası model artık yalnızca "sonuç" vermemektedir; tereddüdünü de davranışıyla göstermektedir.
Regression tarafında ne değişir?
Regresyon problemlerinde ise conformal prediction genellikle tek bir sayı yerine bir prediction interval üretir.
Bu çok önemli bir farktır.
Örneğin bir modelin "Bu evin fiyatı 8 milyon TL" demesi ile "Bu evin fiyatı büyük olasılıkla 7.6 ile 8.4 milyon TL arasında" demesi aynı şey değildir. İkinci ifade, tahminin etrafındaki oynaklığı ve belirsizliği görünür kılar.
Regresyonda conformal prediction'ın cazibesi tam burada ortaya çıkar: tek bir tahmini "sanki kesin bir gerçekmiş gibi" sunmak yerine, tahminin çevresine kontrollü bir aralık yerleştirir.
Bu aralığın genişliği de bize çok şey anlatır. Dar bir aralık, modelin bu örnekte daha yüksek istikrarla çalıştığını düşündürebilir. Geniş bir aralık ise daha fazla belirsizlik olduğunu gösterir.
Üstelik burada önemli bir denge vardır:
- Daha yüksek güven düzeyi istiyorsanız, aralık genellikle genişler.
- Daha dar aralık istiyorsanız, daha fazla hata riskini kabul etmeniz gerekir.
Yani conformal prediction, kullanıcıya örtük değil açık bir tercih sunar: Ne kadar kapsayıcılık istiyorum, bunun karşılığında ne kadar belirsizlik kabul ediyorum?
Bu, teori ile uygulamanın çok güzel buluştuğu noktalardan biridir.
Bu yaklaşım neden bu kadar etkileyici?
Conformal prediction'ın bu kadar ilgi çekmesinin birkaç nedeni var.
İlk olarak, belirsizlik konusunu soyut bir fikir olmaktan çıkarıp pratik bir çerçeveye dönüştürüyor. Yani "Modelin biraz emin olmadığı durumlar var" gibi muğlak bir cümle yerine, daha kontrol edilebilir bir yapı sunuyor.
İkinci olarak, mevcut bir modelin üzerine eklenebilen bir yaklaşım olarak düşünülebiliyor. Bu da onu teorik olduğu kadar pratik açıdan da çekici yapıyor. Baştan tamamen yeni bir sistem kurmak yerine, var olan tahmin yapısını daha güvenli ve daha yorumlanabilir hale getirmek mümkün olabiliyor.
Üçüncü olarak, kullanıcıya çok doğal bir soru üzerinden kontrol sağlıyor: Ne kadar hata toleransım var? Bu soru, birçok iş probleminde teknik metriklerden daha anlamlıdır. Çünkü karar vericiler çoğu zaman model mimarisini değil, kabul edilebilir risk seviyesini düşünür.
Conformal prediction bu açıdan güçlüdür: belirsizliği yalnızca ölçmez, aynı zamanda onu karar diliyle konuşulabilir hale getirir.
Ama kusursuz bir çözüm mü?
Hayır.
Conformal prediction çok güçlü bir çerçeve olsa da sihirli bir değnek değildir. Verinin kalitesi, dağılımın zaman içinde değişmesi, kalibrasyon setinin yeterliliği ve problemin yapısı gibi unsurlar sonuçları ciddi biçimde etkileyebilir.
Daha açık söylemek gerekirse, conformal prediction kötü bir modeli otomatik olarak iyi yapmaz. Zayıf veri temsilini sihirli biçimde düzeltmez. Veri dağılımı ciddi şekilde kayıyorsa, teoride beklediğimiz davranış pratikte bozulabilir.
Bu yüzden conformal prediction'ı en doğru biçimde şöyle görmek gerekir:
Bu yaklaşım belirsizliği görünür kılar; ama problemi ortadan kaldırmaz. Bize daha dürüst, daha kontrollü ve daha yorumlanabilir çıktılar sunar. Ama hâlâ dikkatli tasarım, iyi veri ve sağlıklı değerlendirme gerekir.
Sonuç
Makine öğrenmesinde uzun süre boyunca asıl hedefin mümkün olan en doğru tahmini yapmak olduğu düşünüldü. Bu elbette hâlâ önemli. Ama bugün giderek daha net görüyoruz ki, birçok gerçek dünya probleminde yalnızca doğru tahmin yetmiyor.
Asıl ihtiyaç, modelin ne zaman güvenilir konuştuğunu ve ne zaman temkinli olunması gerektiğini anlayabilmek.
Conformal prediction bu ihtiyaca güçlü bir teorik cevap veriyor. Çünkü tek bir tahmin üretmek yerine, tahminin etrafına bir güven çerçevesi ekliyor. Sınıflandırmada olası etiket kümeleri, regresyonda ise tahmin aralıkları üreterek modelin belirsizliğini daha görünür hale getiriyor.
Belki de en önemli katkısı şu: Modeli olduğundan daha emin göstermeye çalışmıyor. Tam tersine, onun sınırlarını daha dürüst bir şekilde ortaya koyuyor.
Ve belki de güvenilir yapay zekâya giden yolda en çok ihtiyacımız olan şey tam olarak bu.
Bir sonraki adımda doğal olarak şu soru geliyor: Peki modelin ürettiği olasılıkların kendisi ne kadar güvenilir?
Örneğin bir model "Ben bu tahminden yüzde 80 eminim" diyorsa, gerçekten uzun vadede bu yüzde 80 ifadesine güvenebilir miyiz?
İşte bu soru bizi calibration dünyasına götürüyor. Bir sonraki yazıda isotonic regression, logistic calibration ve Venn-Abers gibi yöntemlerle, model olasılıklarının ne kadar güvenilir hale getirilebileceğine bakabiliriz.

